Introduction
The similarity self-join is an operation that finds all objects in a dataset within a distance threshold of each other. A typical method for the self-join is to utilize the search-and-refine strategy: search a set of candidate points that may be within the search radius for every query point, and then refine them by performing the distance calculations. Numerous searches for points within the search distance take advantage of the GPU’s high memory bandwidth and massive parallelism. Thus, the GPU’s architecture is suitable for massively parallel range queries and join operations.
Optimization
There are many ways for points indexing, divided into two categories: Tree-based indexes (such as R-trees, quad-trees and kd-trees), and non-hierarchical indexes (such as Grids, see Figure 1). Due to the GPU’s SIMT architecture, tree indexes cause divergence in workload among the groups of threads in GPU call warp, so the total performance is depend on the threads in a warp that needs the longest time. On the other hands, each thread performs similar execution pathways in Grid structure. However, we may still have various number of points in different cells in a grid, which is also not very efficient in SIMT architecture.
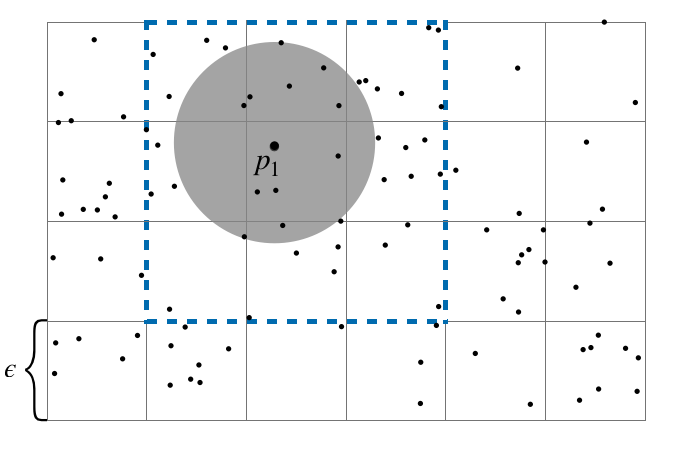
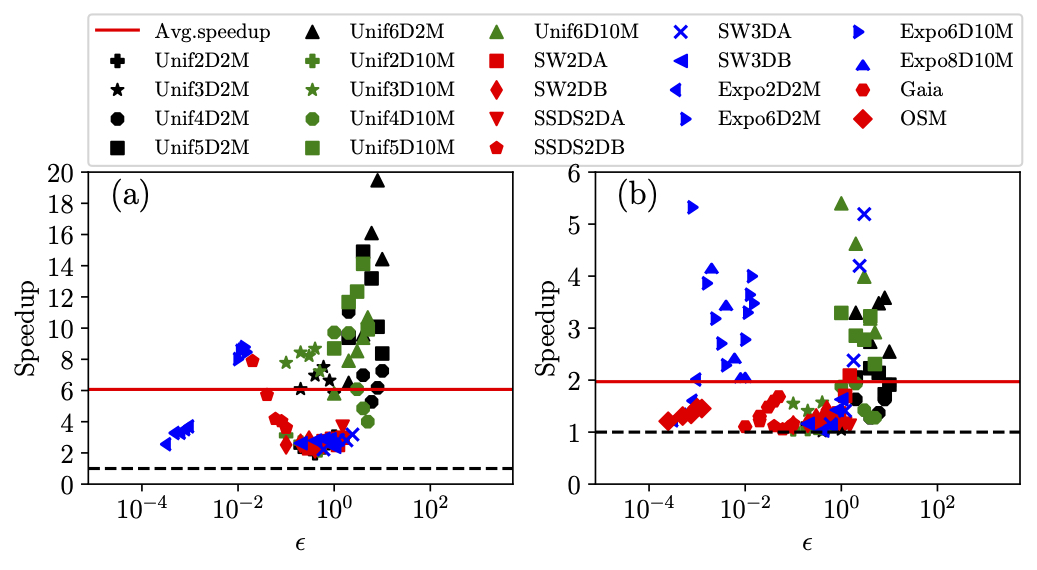
Our goal is to minimize the divergence of workload among each threads. To achieve that, we utilize the grid structure, improve it and develop another two grid-base indexing methods. We also extract the feature of datasets to determin which grid indexes we should use, in order to maximize the performance. We have run experiments on differents datasets, synthetic or real-world, and our method generally has better performance, with up to 20x speedup compare to a CPU implementation and up to 5.5x speedup compare to another state-of-art GPU implementation (See Figure 2).
We are currently improving our optimization methods and drafting the related outcomes. To be continued …

